编程不止是一份工作,还是一种乐趣!!!
Hadoop的框架最核心的设计就是HDFS和MapReduce。前面我们已经介绍过HDFS是一个分布式的文件系统,为海量的数据提供了存储能力;MapReduce建立在HDFS基础上,为海量的数据提供了一个计算框架。MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。MR由两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce背后的思想很简单,就是把一些数据通过map来归类,通过reducer来把同一类的数据进行处理,其原理如下所示:

Map阶段的输入来自HDFS中的文件,我们知道文件在HDFS中是被拆分为文件块分布存储的,默认情况下每一个文件块会由一个map任务来处理。Map任务的输出会作为Reduce的输入,Reduce是对数据集进行精简,然后得出相应结果。当然,MapReduce的整个执行过程比描述的会复杂很多,一般过程分为:Split, Map, Shuffle, Reduce, Output几个阶段,我们以一个单词计数的示例来看看各个阶段的作用。
假设我们有一个文件:
hello java
hello c
hello php
hello javascript
hello java language
hello c language
hello php language
hello javascript language
一、Split阶段:得益于HDFS的特性,文件在HDFS中是分块存储的。假设每个文件块包括2行内容的话,一共四个文件块:
| 文件块 | 内容 |
| 0 | hello java hello c |
| 1 | hello php hello javascript |
| 2 | hello java language hello c language |
| 3 | hello php language hello javascript language |
二、Map阶段:每个块由一个map任务来处理,map函数将各个文件块的内容转换成新的key-value对:
| 文件块 | 内容 | Map任务 | map函数输出 |
| 0 | hello java hello c |
Map任务0 | [hello:1] [java:1] [hello:1] [c:1] |
| 1 | hello php hello javascript |
Map任务1 | [hello:1] [php:1] [hello:1] [javascript:1] |
| 2 | hello java language hello c language |
Map任务2 | [hello:1] [java:1] [language:1] [hello:1] [c:1] [language:1] |
| 3 | hello php language hello javascript language |
Map任务3 | [hello:1] [php:1] [language:1] [hello:1] [javascript:1] [language:1] |
三、Shuffle阶段:这个阶段比较复杂,每个Mapper任务首先会根据Reducer的任务数量对key-value对进行分区,然后对每个分区的key进行排序和分组,执行Combiner,最后发送给Reducer任务。
| Map任务 | map函数输出 | 分区 | 排序 | 分组 | Combiner |
| Map任务0 | [hello:1] [java:1] [hello:1] [c:1] |
分区0 [hello:1],[java:1],[hello:1] 分区1 [c:1] |
分区0 [hello:1],[hello:1],[java:1] 分区1 [c:1] |
分区0 [hello:{1,1}],[java:1] 分区1 [c:1] |
分区0 [hello:2],[java:1] 分区1 [c:1] |
| Map任务1 | [hello:1] [php:1] [hello:1] [javascript:1] |
分区0 [hello:1],[php:1],[hello:1] 分区1 [javascript:1] |
分区0 [hello:1],[hello:1],[php:1] 分区1 [javascript:1] |
分区0 [hello:{1,1}],[php:1] 分区1 [javascript:1] |
分区0 [hello:2],[php:1] 分区1 [javascript:1] |
| Map任务2 | [hello:1] [java:1] [language:1] [hello:1] [c:1] [language:1] |
分区0 [hello:1],[java:1],[hello:1] 分区1 [language:1],[c:1],[language:1] |
分区0 [hello:1],[hello:1],[java:1] 分区1 [c:1],[language:1],[language:1] |
分区0 [hello:{1,1}],[java:1] 分区1 [c:1],[language:{1,1}] |
分区0 [hello:2],[java:1] 分区1 [c:1],[language:2] |
| Map任务3 | [hello:1] [php:1] [language:1] [hello:1] [javascript:1] [language:1] |
分区0 [hello:1],[php:1],[hello:1] 分区1 [language:1],[javascript:1],[language:1] |
分区0 [hello:1],[hello:1],[php:1] 分区1 [javascript:1],[language:1],[language:1] |
分区0 [hello:{1,1}],[php:1] 分区1 [javascript:1],[language:{1,1}] |
分区0 [hello:2],[php:1] 分区1 [javascript:1],[language:2] |
四、Reduce阶段:Shuffle结束后,同一分区的数据会传送给同一个Reducer任务。Reducer任务接收到key-value对后会先根据key进行排序和分组,最后执行Reducer函数输出结果。
| Reduce任务 | 输入 | 排序 | 分组 | 输出 |
| Reduce任务0 | [hello:2] [java:1] [hello:2] [php:1] [hello:2] [java:1] [hello:2] [php:1] |
[hello:2] [hello:2] [hello:2] [hello:2] [java:1] [java:1] [php:1] [php:1] |
[hello:{2,2,2,2}] [java:{1,1}] [php:{1,1}] |
[hello:8] [java:2] [php:2] |
| Reduce任务1 | [c:1] [javascript:1] [c:1] [language:2] [javascript:1] [language:2] |
[c:1] [c:1] [javascript:1] [javascript:1] [language:2] [language:2] |
[c:{1,1}] [javascript:{1,1}] [language:{2,2}] |
[c:2] [javascript:2] [language:4] |
老的MapReduce架构(俗称MapReduce 1)主要包括Job Tracker和Task Tracker。客户端提交任务给Job Tracker,Job Tracker与集群所有机器通信(heartbeat),管理所有job失败、重启等操作。Task Tracker是在每一台机器上都有的,主要用来监视自己所在机器的task运行情况及机器的资源情况,然后把这些信息通过heartbeat发送给Job Tracker。
MapReduce 1存在的问题:
为了解决这些问题,YARN(俗称MapReduce 2)出现了,它主要分为三个组件:Resource Manager、Node Manager和Application Master。Resource Manager负责全局资源分配;每个应用程序包含一个ApplicationMaster,它可以运行在ResourceManager以外的机器上,负责当前应用程序的调度和协调;Node Manager是每台机器的代理,监控应用程序的资源使用情况,并汇报给Resource Manager。因此与老的MapReduce相比,YARN把资源管理与任务调度的工作分离开来,减少了MapReduce中Job Tracker的压力。其基本架构图如下:

相比于MapReduce 1,YARN主要优势如下:
在《HDFS简介》中我们已经搭建了一个HDFS集群,现在我们接着在上面搭建一个Yarn环境。
一、修改mapred-site.xml文件(三台服务器一样)
<property>
<!--指定Mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--Larger resource limit for maps-->
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<property>
<!--Larger resource limit for reduces.-->
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
</property>
<property>
<!--Higher memory-limit while sorting data for efficiency.-->
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1536</value>
</property>
二、修改yarn-site.xml文件(三台服务器一样)
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.161</value>
</property>
<property>
<!--For ResourceManager Only-->
<!--ResourceManager对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等-->
<name>yarn.resourcemanager.address</name>
<value>192.168.0.161:8032</value>
</property>
<property>
<!--For ResourceManager Only-->
<!--ResourceManager对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.0.161:8030</value>
</property>
<property>
<!--For ResourceManager Only-->
<!--ResourceManager对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.0.161:8031</value>
</property>
<property>
<!--For ResourceManager Only-->
<!--ResourceManager对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等-->
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.0.161:8033</value>
</property>
<property>
<!--For ResourceManager Only-->
<!--ResourceManager对外Web UI地址。用户可通过该地址在浏览器中查看集群各类信息-->
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.0.161:8088</value>
</property>
<property>
<!--For ResourceManager Only-->
<!--单个可申请的最小内存资源量-->
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<!--For ResourceManager Only-->
<!--整个集群的可又支配内存总量-->
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<property>
<!--For NodeManager Only-->
<!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--For NodeManager Only-->
<!--中间结果存放位置,类似于1.0中的mapred.local.dir。注意,这个参数通常会配置多个目录,已分摊磁盘IO负载-->
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/local/bigdata/nm-local-dir</value>
</property>
<property>
<!--For NodeManager Only-->
<!--日志存放地址(可配置多个目录)-->
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/local/bigdata/nm-log-dir</value>
</property>
<property>
<!--For NodeManager Only-->
<!--NodeManager总的可用物理内存-->
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
三、创建临时目录与日志目录(三台服务器一样):
mkdir /opt/local/bigdata/nm-log-dir
mkdir /opt/local/bigdata/nm-local-dir
四、在192.168.0.161服务器启动resourcemanager进程:
/opt/local/hadoop-2.6.5/sbin/yarn-daemon.sh start resourcemanager
五、在192.168.0.162与192.168.0.163服务器启动nodemanager进程:
/opt/local/hadoop-2.6.5/sbin/yarn-daemon.sh start nodemanager
六、在192.168.0.161服务器启动作业日志服务:
/opt/local/hadoop-2.6.5/sbin/mr-jobhistory-daemon.sh start historyserver
现在我们可以通过http://192.168.0.161:8088访问Yarn控制平台了,http://192.168.0.161:19888访问MR作业日志服务了
也可能像启动HDFS集群那样,使用start-yarn.sh命令启动Yarn集群。
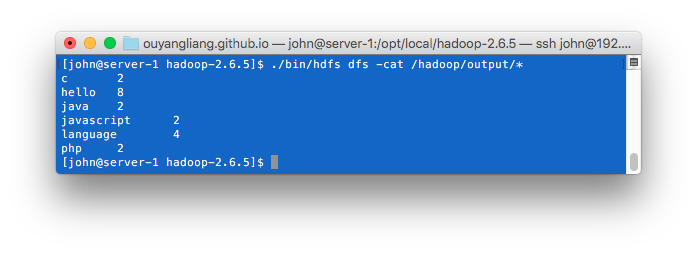
首先,将测试的文件上传到HDFS中:
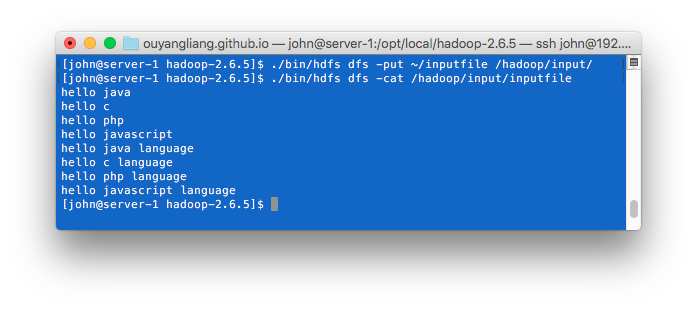
执行单词计数的程序,源码可以在这里查看:
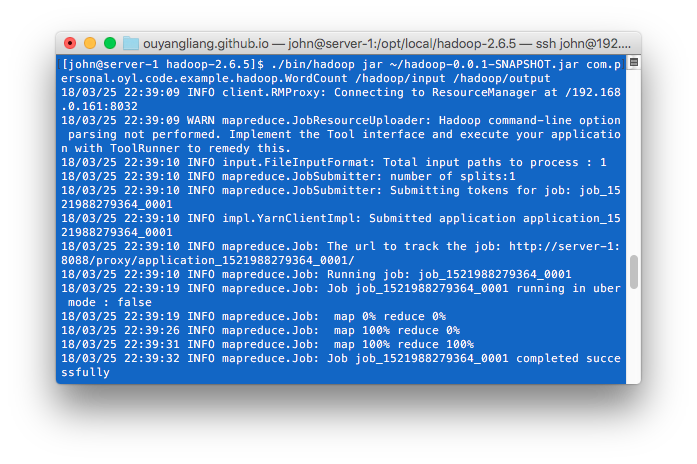
查看执行结果,与我们之前的分析是一致的: