编程不止是一份工作,还是一种乐趣!!!
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算框架。
HDFS中文件在物理上是分块存储的,块的大小可以通过配置参数(dfs.blocksize)来设置。默认大小在hadoop2.x版本中是128M,老版本中的64M。
HDFS集群分为两大角色:NameNode、DataNode。NameNode负责管理整个文件系统的元数据,DataNode负责管理文件数据块。
文件会按照固定的大小切成若干分块后分布式存储在若干台DataNode上。同一个文件块可以有多个副本(dfs.replication),并存放在不同的DataNode上。
DataNode会定期向NameNode汇报自身保存的块信息,而NameNode则会负责保证文件块的副本数量。
HDFS的内部工作机制对客户端透明,客户端访问HDFS通过NameNode进行。
HDFS适应一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用(因为不方便进行修改,延迟大,网络开销大,成本太高)
在HDFS集群中,主要有三类角色:NameNode、DataNode和客户端,其结构如下所示:

NameNode
NodeName是HDFS集群中的主节点,目录结构信息、文件与数据块的对应关系,这些信息会持久化到NameNode的本地磁盘中,叫做fsimage。而文件块存放在哪些DataNode节点,这个对应关系会在DataNode启动时会上报给NameNode,这个对应关系是保存在NameNode的内存中的。这个信息是动态建立的过程,因此,集群的启动可能需要比较长的时间。
DataNode
DataNode是HDFS中的从节点,它是干活的。负责存储文件块的内容、定期向NameNode汇报自身保存的块信息。另外,还接收NameNode的命令执行操作,比如复制,删除等操作。
HDFS客户端
HDFS集群的使用者,HDFS给客户端提供统一的抽象目录树,客户端通过路径来访问文件,形如hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
SecondaryNameNode
从它的名字上看,它给人的感觉就像是NameNode的备份,但它实际上却不是。NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的,但是这些信息也可以持久化到磁盘上:

上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力,也就是Secondary NameNode存在的意义了:它的职责是合并NameNode的edit logs到fsimage文件中。

上面的图片展示了Secondary NameNode是怎么工作的。它定时到NameNode去获取edit logs,并更新到自己的fsimage上。一旦它有了新的fsimage文件,它将其拷贝回NameNode中。NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。
我们使用三台服务器(192.168.0.161, 192.168.0.162, 192.168.0.163)来构建一个HDFS集群,其中192.168.0.161为NameNode,192.168.0.162与192.168.0.163为DataNode。
一、将hadoop安装文件分别解压到各个服务器的/opt/local目录下面:
sudo tar -zxvf hadoop-2.6.5.tar.gz -C /opt/local
二、修改hadoop安装文件所有者权限(三台服务器一样):
chown -R john:john hadoop-2.6.5
三、修改hadoop-env.sh文件,设置JAVA_HOME:
export JAVA_HOME=/opt/local/jdk1.8.0_151
四、修改core-site.xml文件(三台服务器一样)
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.161:9000</value>
</property>
五、修改hdfs-site.xml文件(三台服务器一样)
<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster</value>
<description>在一个全分布式集群当中这个的值要相同</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/local/bigdata/name</value>
<description>DFS name node 存放 name table 的目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/local/bigdata/data</value>
<description>DFS data node 存放数据 block 的目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>分布式文件系统数据块复制数</description>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
</configuration>
六、创建/opt/local/bigdata目录(三台服务器一样):
sudo mkdir /opt/local/bigdata
sudo chown -R john:john bigdata
mkdir /opt/local/bigdata/name
mkdir /opt/local/bigdata/data
七、在NameNode服务器格式化HDFS文件系统:
/opt/local/hadoop-2.6.5/bin/hdfs namenode -format
八、在NameNode服务器启动namenode进程:
/opt/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start namenode
九、在DataNode服务器启动datanode进程:
/opt/local/hadoop-2.6.5/sbin/hadoop-daemon.sh start datanode
现在我们可以通过http://192.168.0.161:50070访问NameNode控制平台了,可以看到192.168.0.162和192.168.0.163两台DataNode。
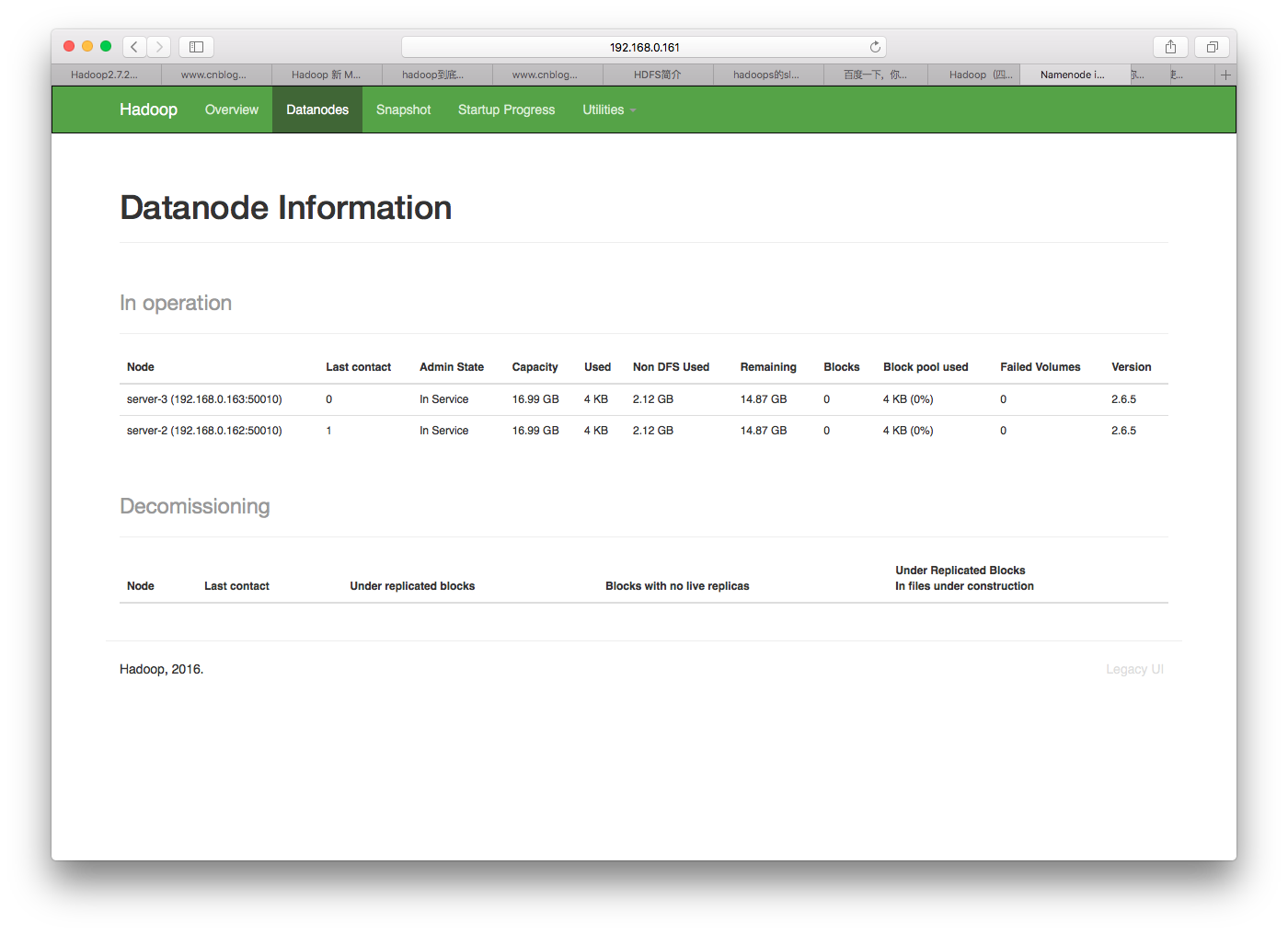
现在我们来测试一下集群,进行一些简单的操作。客户端可以直接用三台服务器中任意一台,也可以单独使用一台其它机器。如果使用单独的机器,需要修改core-site.xml文件,让客户端知道NameNode服务器的地址。为了简单,我们直接在NameNode服务器上测试:
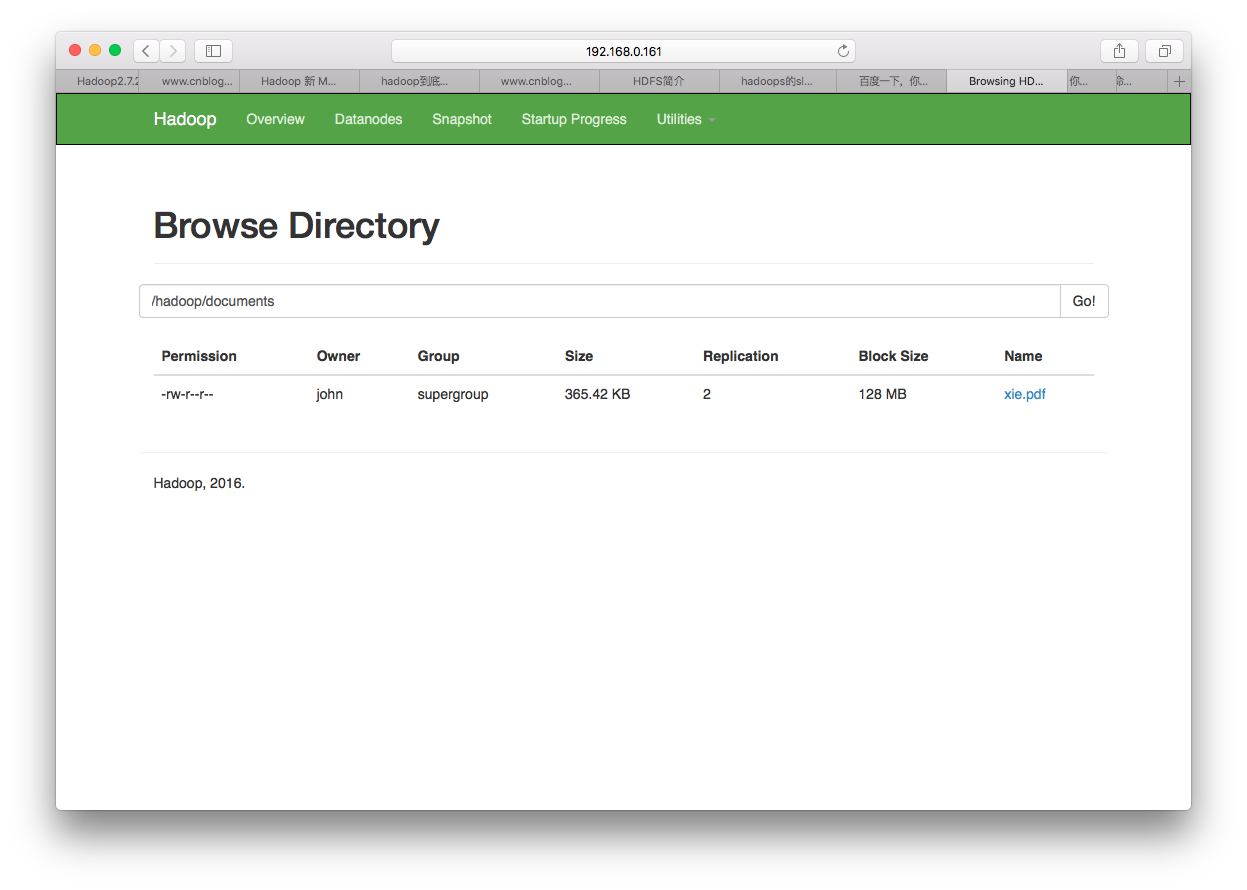
./bin/hdfs dfs -mkdir -p /hadoop/documents
./bin/hdfs dfs -put ~/xie.pdf /hadoop/documents/
我们先在HDFS创建一个目录/hadoop/documents,然后将一个本地文件上传到HDFS中这个目录,所下所示:
HDFS集群搭建的资料在网上有很多,大部分都提到了SSH免密登录,修改slave文件,但我们前面的介绍并未涉及,为什么呢?在生产中,HDFS集群的规模可能非常大,成百上千台服务器,如果按照前面介绍的方法手动启动每一台DataNode服务器,将会是一场恶梦。这时就要看slave文件了,slave文件的内容是所有DataNode服务器的清单,这样在NameNode启动时,他能根据该文件的内容自动启动远程的DataNode服务。当然,为了使这个过程自动化还需要一个条件:
配置好slave和ssh免密登录后,启动整个集群的工作就非常简单了,只需要在NameNode中执行下面的命令即可:
/opt/local/hadoop-2.6.5/sbin/start-dfs.sh