编程不止是一份工作,还是一种乐趣!!!
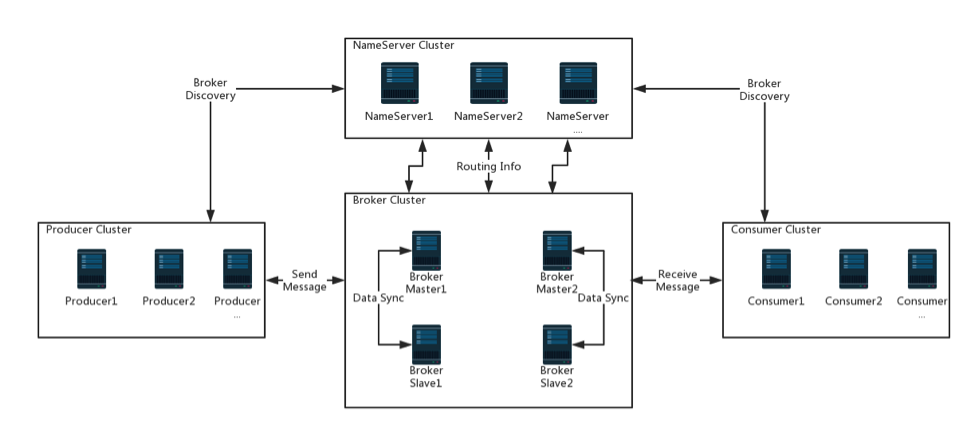
在RocketMq集群中,有NameServer、Broker、Producer集群、Consumer集群等,下面我们分别介绍:
NameServer
Name Server是RocketMQ的寻址服务,客户端通过Name Server去获取对应Broker和Topic的路由信息,从而跟相关的Broker建立连接。Name Server是一个几乎无状态的结点,Name Server之间采取share-nothing的设计,互不通信。
对于一个Name Server集群列表,客户端连接Name Server的时候,只会选择随机连接一个结点,以实现Name Server的负载均衡。
Name Server所有状态都从Broker上报而来,本身不存储任何状态,所有数据均在内存。
如果中途所有Name Server全都挂了,只会影响路由信息的更新,不会影响客户端和Broker的通信。
Broker
Broker以group分开,每个group只允许一个Master,若干个Slave。
只有Master才能进行写入操作,Slave不允许。
Slave从Master中同步数据,同步策略取决于Master的配置,支持同步双写和异步复制两种策略。
客户端消费可以从Master和Slave消费。默认情况下,消费者都从Master消费,在Master挂后,客户端从Name Server中感知到Broker宕机,会降级从Slave消费。
Broker向所有的NameServer结点建立长连接,注册Topic信息。
Producer
生产者,发送消息的客户端角色。
Consumer
消费者,消费消息的客户端角色。通常是后台处理异步消费的系统。
RocketMQ中Consumer有两种实现:PushConsumer和PullConsumer。
PushConsumer
推送模式(RocketMQ使用的是长轮询)的消费者。消息的能及时被消费。使用非常简单,内部已处理如线程池消费、流控、负载均衡、异常处理等等的各种场景。
PullConsumer
拉取模式的消费者。应用主动控制拉取的时机,怎么拉取,怎么消费等。主动权更高。但要自己处理各种场景。
Producer Group
标识发送同一类消息的Producer,通常发送逻辑一致。发送普通消息的时候,仅标识使用,并无特别用处。
若事务消息,如果某条发送某条消息的Producer宕机,使得事务消息一直处于PREPARED状态并超时,则Broker会回查同一个group的其他Producer,确认这条消息应该commit还是rollback。但开源版本并不支持事务消息。
Consumer Group
标识一类Consumer的集合名称,这类Consumer通常消费一类消息,且消费逻辑一致。同一个Consumer Group下的各个实例将共同消费Topic的消息,起到负载均衡的作用。消费进度以Consumer Group为粒度管理,不同Consumer Group之间消费进度彼此不受影响,即同一消息被Consumer Group1消费过,也会再给Consumer Group2消费。
注: RocketMQ要求同一个Consumer Group的消费者必须要拥有相同的注册信息,即必须要听一样的Topic(并且Tag也一样)。
Topic
与Kafka Topic含义相同,标识同类消息的逻辑名字。无论消息生产还是消费,都需要指定Topic。
Message Queue
类似于Kafka的Partition,消息物理管理单位。一个Topic可以分成若干个Queue,通常分布在不同的Broker上,具有水平扩展的能力。无论生产者还是消费者,实际的生产和消费都是针对Queue级别。例如Producer发送消息的时候,会预先选择(默认轮询)好该Topic下面的某一个Queue发送;Consumer消费的时候也会负载均衡地分配若干个Queue,只拉取对应Queue的消息。每一条Message Queue都对应一个索引文件,这个文件存储了实际消息的索引信息,实际的消息内容文件存在Commit Log文件中。
Tag
Tag是RocketMQ特有的概念,在发送消息的时候除了需要指定Topic外,还可以指定Tag。同一个Topic的消息虽然逻辑管理是一样的,但是消费Topic的时候,如果你订阅的时候指定的是tagA,那么tagB的消息将不会投递。比如有个商品的消息,就可以使用Tag来区分品类,使用不同的Consumer Group来处理不同品类的商品消息。
Offset
与Kafka是一样的,在RocketMQ中,可以把Message Queue理解成一个无限长的数组,每条消息进来下标就会加1,而这个数组的下标就是Offset。Consumer拉取消息的时候需要指定Offset,Broker不主动推送消息。Consumer刚启动的时候会获取在Broker上持久化的Consumer Offset,用以确定从哪里开始消费,Consumer以此发起第一次请求。每次消息消费成功后,这个Offset在会先更新到内存,随后持久化。在集群消费模式下,会同步持久化到Broker,而在广播模式下,则会持久化到客户端本地文件。
集群消费
消费者的一种消费模式。一个Consumer Group中的各个Consumer实例分摊去消费消息,即一条消息只会投递到一个Consumer Group下面的一个实例。实际上,每个Consumer是平均分摊Message Queue的去做拉取消费。例如某个Topic有3条Queue,其中一个Consumer Group有3个实例(可以是3个线程),那么每个实例只消费其中的1条Queue。而由Producer发送消息的时候是轮询所有的Queue,所以消息会平均散落在不同的Queue上,可以认为Queue上的消息是平均的。那么实例也就平均地消费消息了。这种模式下,每个Consumer Group的消费进度(即当前的Offset)会持久化到Broker。
广播消费
消费者的另一种消费模式,Kafka不支持这种模式。消息将对一个Consumer Group下的每个Consumer都投递一遍,即使这些Consumer属于同一个Consumer Group,消息也会被Consumer Group中的每个Consumer都消费一次。实际上,Consumer Group下的每个Consumer都会到Topic下面的每个Message Queue去拉取消费,所以消息会投递到每个Consumer。这种模式下,消费进度会存储持久化到实例本地。
顺序消费
消费消息的顺序要同发送消息的顺序一致。由于Consumer消费消息的时候是针对Message Queue顺序拉取并开始消费,且一条Message Queue只会给一个消费者(集群模式下),所以能够保证同一个消费者实例对于Queue上消息的消费是顺序地开始消费(不一定顺序消费完成,因为消费可能并行)。
同Kafka Partition一样,在RocketMQ中,顺序消费主要指的是都是Queue级别的顺序。为了满足顺序,Producer必须单线程顺序发送,可以用MessageQueueSelector为消息选择一个Queue,这样Consumer就可以按照Producer发送的顺序去消费消息。
普通顺序消费
顺序消费的一种,正常情况下可以保证完全的顺序消费,但一旦发生异常,Broker宕机或重启,由于队列总数发生发化,消费者会触发负载均衡,而默认地负载均衡算法采取哈希取模平均,这样负载均衡分配到定位的队列会发化,使得队列可能分配到别的实例上,则会短暂地出现消息顺序不一致。如果业务能容忍在集群异常情况(如某个Broker宕机或者重启)下,消息短暂的乱序,使用普通顺序方式比较合适。
严格顺序消费
顺序消息的一种,无论正常异常情况都能保证顺序,但是牺牲了可用性,即Broker集群中只要有一台机器不可用,则整个集群都不可用,服务可用性大大降低。如果服务器部署为同步双写模式,可通过备机自动切换为主避免,不过仍然会存在几分钟的服务不可用。
Broker是以Group为单位提供服务。一个Group里面分Master和Slave,Slave从Master同步数据,支持同步双写和异步复制两种策略。
Broker通过Name Server暴露给客户端后,客户端会感知Topic的路由信息,实际上是Message Queue的路由信息。这些Message Queue分布在不同的Broker Group,所以对于客户端来说,请求会分布到不同的Broker Group,这样消息的存储和转发均起到了负载均衡的作用。
同一个Topic在不同的Broker Group下是完全独立的,比如Group 1下Topic a有4个Message Queue,Group 2下Topic a可以是2个Message Queue,这样Group 1也承担了更大的负载。而且,当Broker需要横向扩展时,只需要增加Broker Group,然后把对应的Topic建上,Topic对应的Message Queue集合就会变大,这样对于Broker的负载就会由更多的Broker Group来进行分担。
每个实例在发消息的时候,默认会轮询所有的Message Queue发送,以实现消息平均落在不同的Broker上,如下图:

在集群模式下,每条消息只需要投递到Consumer Group下的一个Consumer。当Consumer Group下的Consumer数量有变化,或者Topic的Message Queue有变化(Broker宕机或有新的Broker Group加入),都会触发一次Rebalance,这时候会按照Queue的数量和Consumer的数量重新分配。
集群模式默认支持两种分配算法,其中AllocateMessageQueueAveragely算法如下图所示:

还有一种AllocateMessageQueueAveragelyByCircle算法,如下图所增:

集群模式下,RocketMQ的行为与Kakfa是完全一致的。通过增加Consumer去分摊消费,也可以起到水平扩展的作用;但是如果Consumer的数量比Message Queue的总数量还多的话,多出来的Consumer将无法分到Queue,实际上只是起到backup的作用。
广播模式下每条消息需要投递到Consumer Group下面的每一个Consumer,所以也就没有消息被分摊消费的说法。

【注】广播模式下,Offset是存在各个Consumer本地,不会持久化到Broker端。
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("send-group");
producer.setNamesrvAddr("localhost:9876");
producer.start();
for (int i = 0; i < 32; i++) {
Message msg = new Message("TopicTest", "TagA", ("Message " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
producer.shutdown();
}
如果你熟悉Kafka,那RocketMQ的Producer还是非常简单的,这里消息会以轮询的方式分别发送给各个Message Queue。如果需要将消息发送给指定的Queue,可以使用MessageQueueSelector,如下所示:
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("send-group");
producer.setNamesrvAddr("localhost:9876");
producer.start();
for (int i = 0; i < 32; i++) {
Message msg = new Message("TopicTest", "TagA", ("Message " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer idx = (Integer) arg;
return idx < 16 ? mqs.get(0) : mqs.get(1);
}
}, i);
System.out.printf("%s%n", sendResult);
}
producer.shutdown();
}
当TopicTest有两个Message Queue时,上面的Producer会把0 ~ 15的消息发送到Queue 0,16 ~ 31的消息发送到Queue 1。
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("TopicTest-group");
consumer.setNamesrvAddr("localhost:9876");
consumer.setMessageModel(MessageModel.CLUSTERING);
consumer.setConsumeThreadMin(2);
consumer.setConsumeThreadMax(2);
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.subscribe("TopicTest", "TagA");
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
for (MessageExt msg : msgs) {
try {
String message = new String(msg.getBody(), RemotingHelper.DEFAULT_CHARSET);
System.out.println(Thread.currentThread().getName() + ": " + message);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
第一次写RocketMQ的时候,内心是充满疑问的。在Consumer内部,有两个选项是配置最小线程数和最大线程数(上面我们配置的是2个线程),那是不是意味着消息会被并行处理,如果是这样,那还能保证顺序吗?用前面的示例(TopicTest有2个Message Queue时,0 ~ 15的消息发送到Queue 0,16 ~ 31的消息发送到Queue 2)来测试这段代码,输出的结果如下:
Consumer Started.
ConsumeMessageThread_2: Message 0
ConsumeMessageThread_1: Message 16
ConsumeMessageThread_1: Message 17
ConsumeMessageThread_2: Message 1
ConsumeMessageThread_1: Message 18
ConsumeMessageThread_2: Message 2
ConsumeMessageThread_1: Message 19
ConsumeMessageThread_2: Message 3
ConsumeMessageThread_1: Message 20
ConsumeMessageThread_2: Message 4
ConsumeMessageThread_1: Message 21
ConsumeMessageThread_2: Message 5
ConsumeMessageThread_1: Message 22
ConsumeMessageThread_2: Message 6
ConsumeMessageThread_1: Message 23
ConsumeMessageThread_2: Message 7
ConsumeMessageThread_1: Message 24
ConsumeMessageThread_2: Message 8
ConsumeMessageThread_1: Message 25
ConsumeMessageThread_2: Message 9
ConsumeMessageThread_1: Message 26
ConsumeMessageThread_2: Message 10
ConsumeMessageThread_1: Message 27
ConsumeMessageThread_2: Message 11
ConsumeMessageThread_1: Message 28
ConsumeMessageThread_2: Message 12
ConsumeMessageThread_1: Message 29
ConsumeMessageThread_2: Message 13
ConsumeMessageThread_2: Message 14
ConsumeMessageThread_1: Message 30
ConsumeMessageThread_2: Message 15
ConsumeMessageThread_1: Message 31
从结果可以看出,Consumer内部虽然使用两个线程来处理消息,但是Queue 0的消息全部由线程2来处理了,而Queue 1的消息全部由线程1处理了,从Message Queue的角度来看,局部顺序是保持的。上面的输出结果,是先跑了Producer端,把32条消息先写到Broker后再启动Consumer的结果;如果先把Consumer端启起来,再跑Producer把消息写到Broker,那结果就变成了这样:
ConsumeMessageThread_1: Message 0
ConsumeMessageThread_2: Message 1
ConsumeMessageThread_1: Message 2
ConsumeMessageThread_2: Message 3
ConsumeMessageThread_1: Message 4
ConsumeMessageThread_1: Message 5
ConsumeMessageThread_2: Message 6
ConsumeMessageThread_2: Message 7
ConsumeMessageThread_2: Message 8
ConsumeMessageThread_1: Message 9
ConsumeMessageThread_1: Message 10
ConsumeMessageThread_2: Message 11
ConsumeMessageThread_1: Message 12
ConsumeMessageThread_2: Message 13
ConsumeMessageThread_1: Message 14
ConsumeMessageThread_1: Message 15
ConsumeMessageThread_2: Message 16
ConsumeMessageThread_1: Message 17
ConsumeMessageThread_2: Message 18
ConsumeMessageThread_2: Message 19
ConsumeMessageThread_1: Message 20
ConsumeMessageThread_2: Message 21
ConsumeMessageThread_1: Message 22
ConsumeMessageThread_2: Message 23
ConsumeMessageThread_1: Message 24
ConsumeMessageThread_1: Message 25
ConsumeMessageThread_2: Message 26
ConsumeMessageThread_1: Message 27
ConsumeMessageThread_2: Message 28
ConsumeMessageThread_1: Message 29
ConsumeMessageThread_2: Message 30
ConsumeMessageThread_2: Message 31
这一次消息的顺序是保证的,但是是两个线程叫交替在执行,难道前面的假设不成立?带着这个疑问我们去看一下RocketMQ的源码。
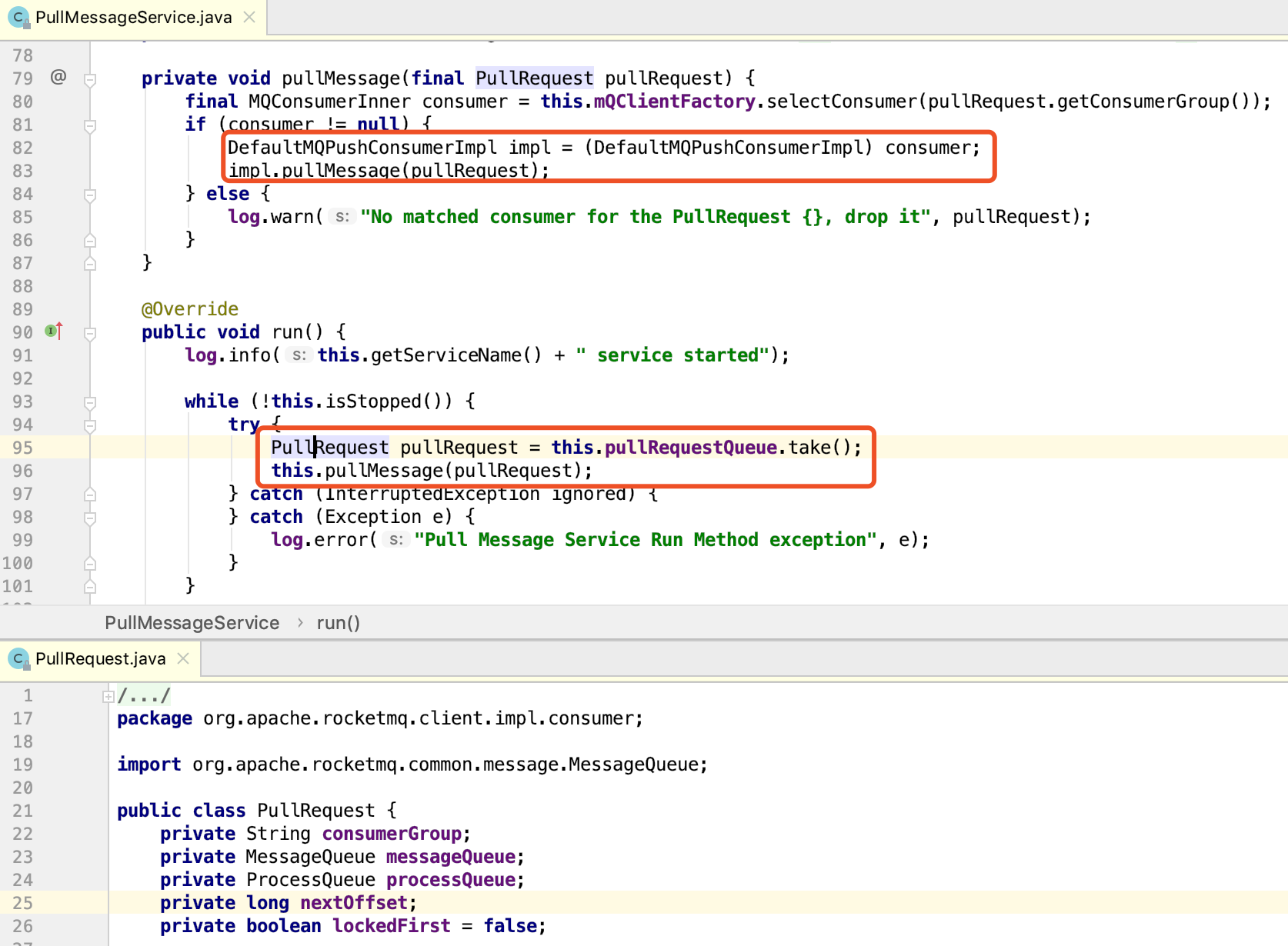
PullMessageService类会不定期的从Broker上拉取消息,从PullRequest对象的源码不难看出,每一次拉取都只局限于一个Message Queue。pull请求实际上是委托给DefaultMQPushConsumerImpl类去做的,在DefaultMQPushConsumerImpl.pullMessage方法内部可以看到,消息从Broker拉到本地后,又委托给ConsumeMessageService类处理。
如下图所示,ConsumeMessageService有两个实现:

我们现在关注的是顺序消费,所以重点看看ConsumeMessageOrderlyService类:
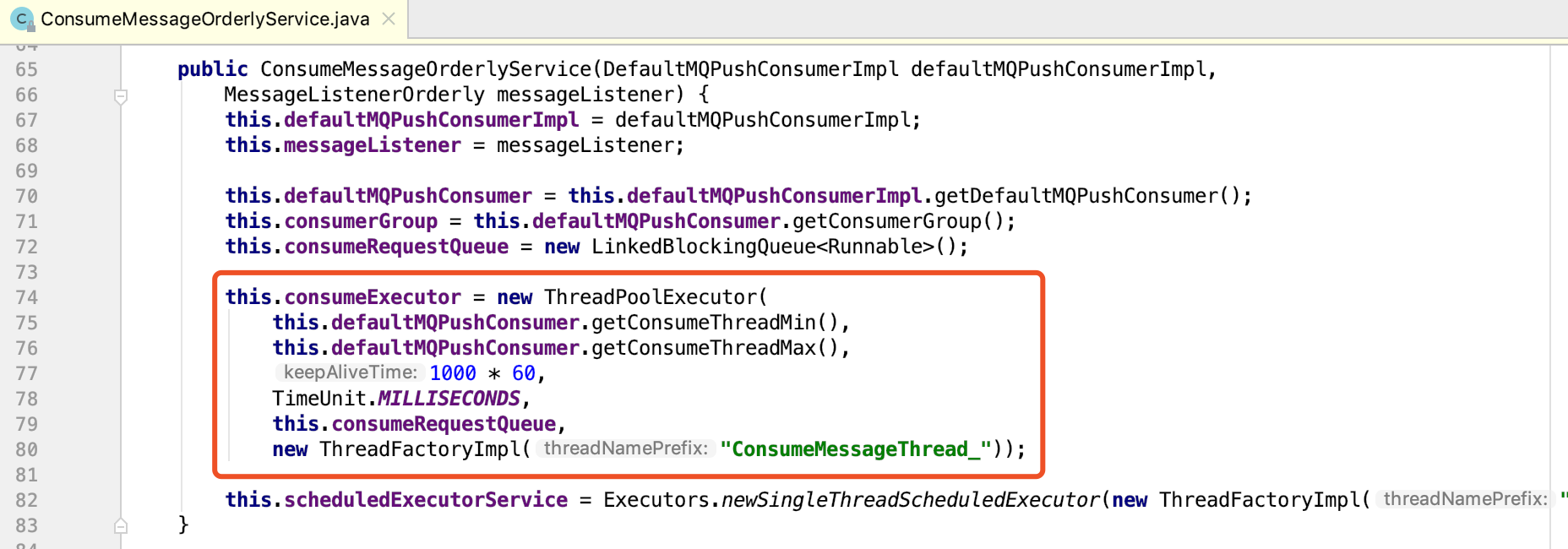
在ConsumeMessageOrderlyService内部定了一个线程池,我们在代码中指定的并行度实际上就是在定义这个线程池的并行线程数。每次从Broker拉取一批消息,最终会被封装到ConsumeMessageOrderlyService.ConsumeRequest中,由同一个线程来执行,如下所示:
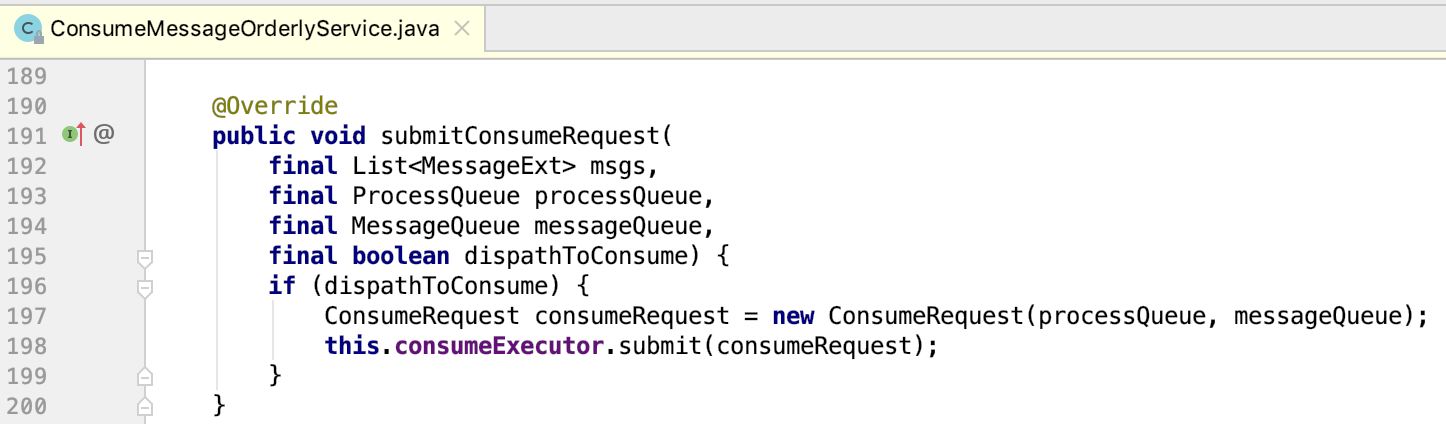
也就是说在顺序消费的情况下,同一个Message Queue上拉下来的一批数据,只会交由一个线程来处理。那会不会存在这样的情况,从同一个Queue上拉下来的第一批数据还没有被处理完,后一批的数据就被拉下来了,并且分配给了另一个线程去处理,这样同一个Queue上的两批数据就会同时被两个线程并发的处理,顺序还是不会被保证。要回答这个问题,就需要看一下ConsumeMessageOrderlyService.ConsumeRequest类的实现:
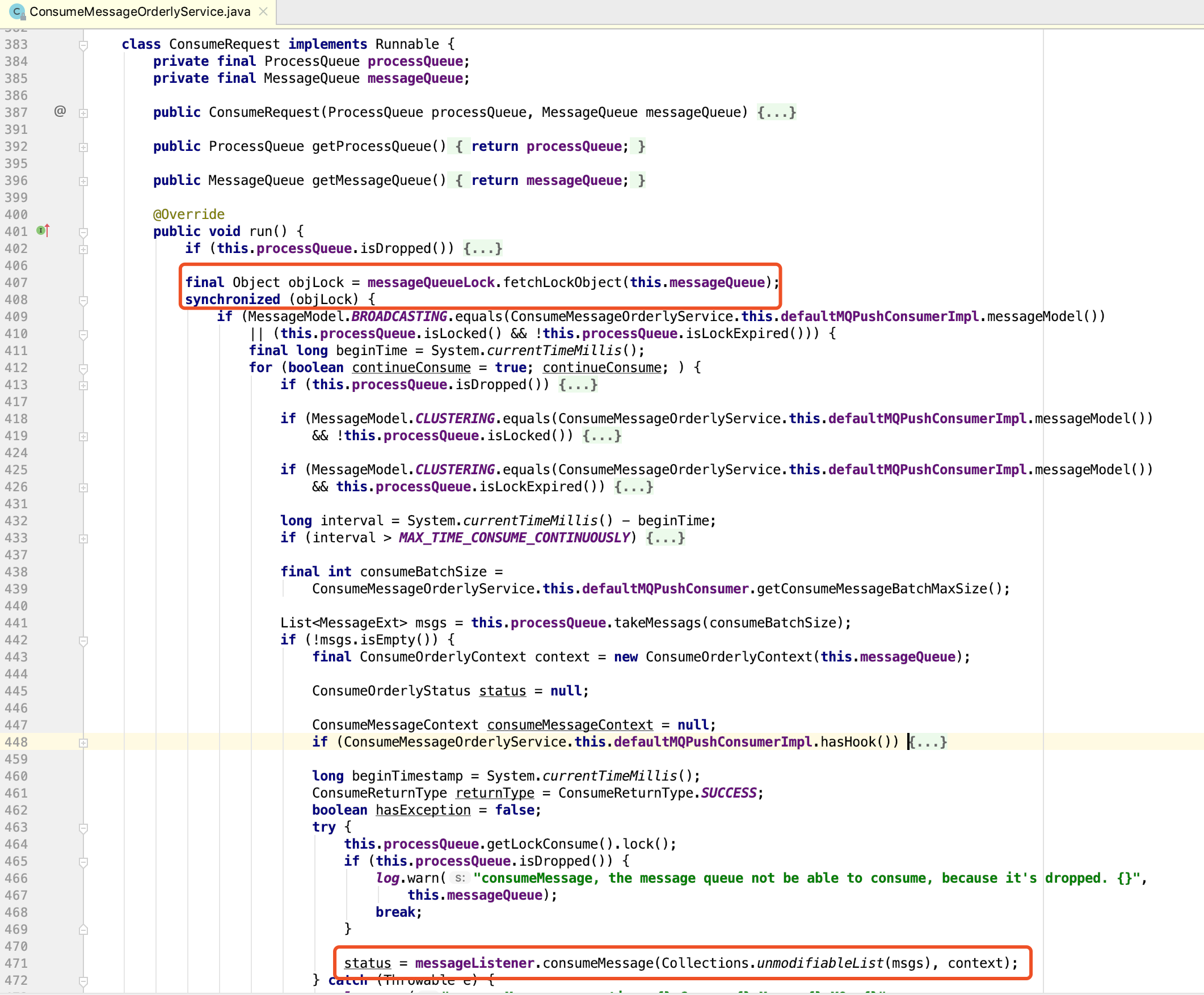
MessageQueueLock内部为每一个Message Queue维护了一个Object对象,在处理每个Queue的消息前会先把Queue对应的Object对象加锁,这样同一个Queue的消息就不可能被并行处理了,从而保证了顺序消费。从代码分析下来,对于顺序消费来说,线程数和分配给当前Consumer的Message Queue的数量能够保持一致是最理想的,多了反而会浪费不必要的资源。
并行消费只需要把MessageListenerOrderly换成MessageListenerConcurrently即可。
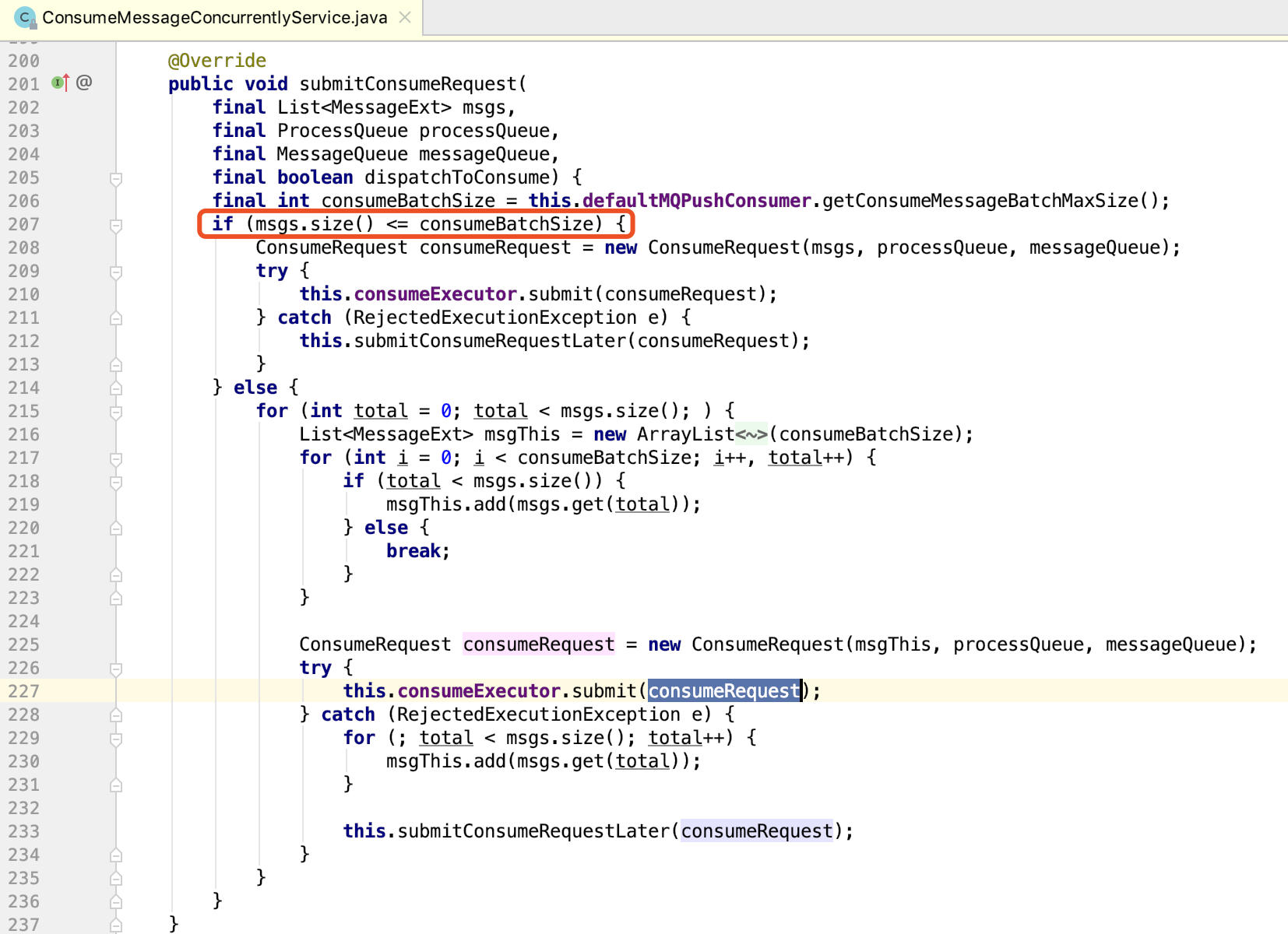
在ConsumeMessageConcurrentlyService内部,会根据consumeBatchSize的值,对一批消息进行拆包,然后并行的处理消息。
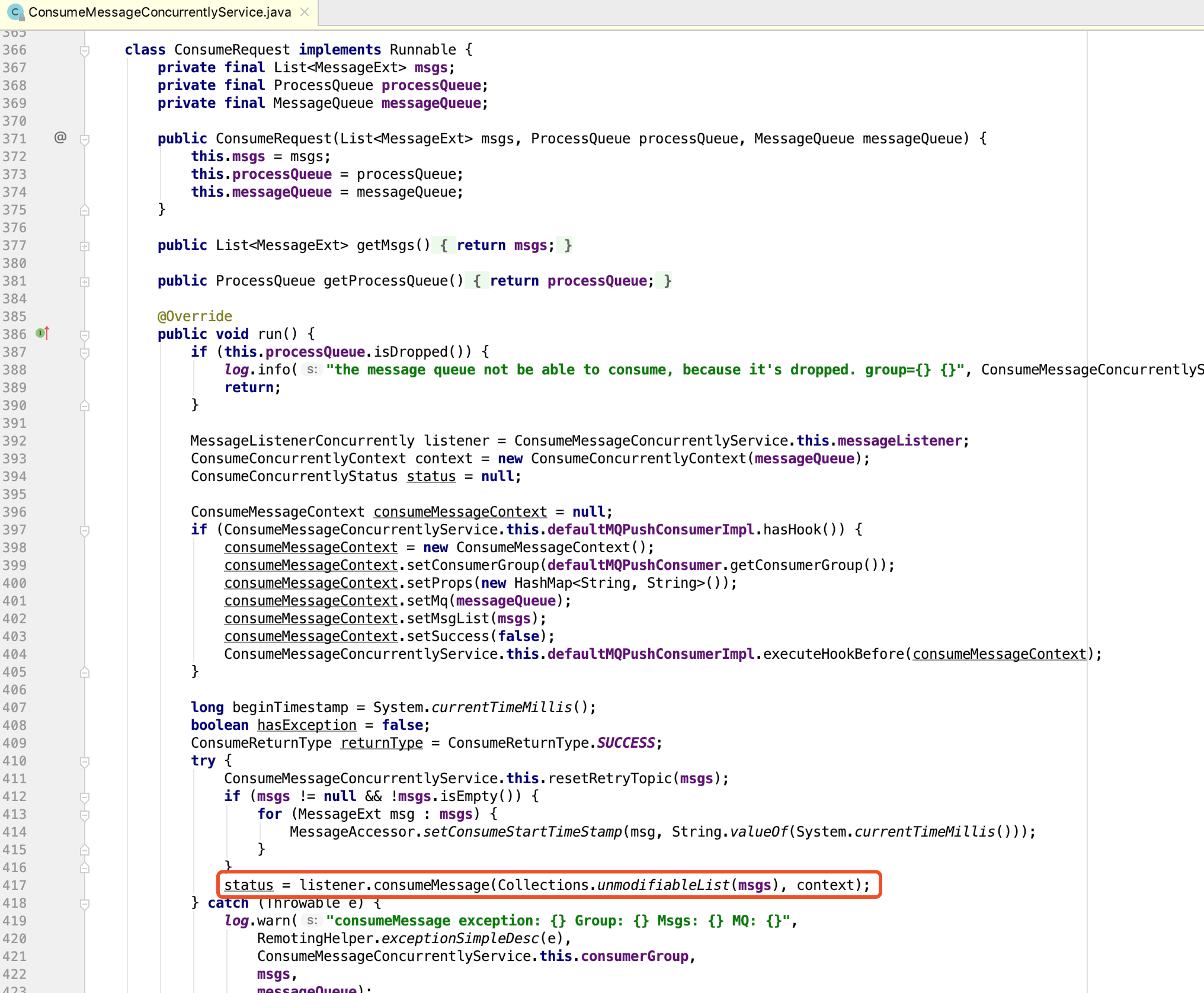
并且,在ConsumeMessageConcurrentlyService.ConsumeRequest内部没有任何的加锁行为,消息的处理完全是并发进行的。当然,线程并不是越多越好,这里需要结合消息的生产速率、Message Queue的数量、Consumer的数量、消费单条消息的效率等多方面一起考量,默认的值是20 ~ 64个线程,通常是没必要给这么高的并发的。
在Producer和Consumer之间传输,有这么几种可能的递交语义:
如果Broker之间是异步复制,Producer向Broker发送一条消息,Master在将这条消息复制到Slave前自己宕机了,Slave通过自动主备切换成为了新的Master,那么这条消息就丢失了,递交语义就变成了At most once;另一种情况,通常我们在发送消息的时候,都会catch异常进行重试。例如网络异常,可能发生在Producer发送消息给Broker时,也可能发生在Broker返回响应给Producer时,对于第二种情况如果我们进行重试,在Message Queue中就会存在重复数据,递交语义就变成了At least once
Kafka 0.11后的版本,在发送消息的时候附带一个序号码实现了幂等,从而实现了生产端的Exactly once,但Rocket MQ目前好像还不支持。
这里我们只分析集群模式。当我们在Consumer代码中返回ConsumeOrderlyStatus.SUCCESS或者ConsumeConcurrentlyStatus.CONSUME_SUCCESS时,RocketMQ会认为这一批消息是消费成功的,会在Broker端更新最新的Offset;但是当消息处理失败时(比如100条消息中,前99个都成功了,最后1个处理失败了),代码里面返回ConsumeConcurrentlyStatus.RECONSUME_LATER或ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT时,RocketMQ会把这批消息重发回Broker(注意:Topic不是原Topic,而是这个Consumer Group的Retry Topic),在某个时间点(默认是10秒)后,再次投递到这个Consumer Group。而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列,应用可以监控死信队列来做人工干预。1个失败的消息导至前面99个成功被处理的消息再次投递,很明显这里我们得到的是At least once的递交语义。
对于一致性要求很高的业务系统来说,消息队列还只是其中的一环,我们要实现端到端的一致性,需要考虑到各个细节。比如经典的银行转账的例子,在消费端为了消除重复消费带来的副作用,数据的更新需要考虑幂等;在生产端除了失败重试机制外,还要考虑极端情况,例如数据库侧已经更新成功,但是消息队列长时候不可用,重试一直失败怎么办?