编程不止是一份工作,还是一种乐趣!!!
生产者消费者问题(英语:Producer-consumer problem),也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了两个共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。

要理解生产消费者问题,首先应弄清PV操作与信号量。信号量的值与相应资源的使用情况有关。当它的值大于0时,表示当前可用资源的数量;当它的值小于0时,其绝对值表示等待使用该资源的线程个数,信号量的值仅能由PV操作来改变。一般来说,信号量S>=0时,S表示可用资源的数量。执行一次P操作意味着请求分配一个单位资源,因此S的值减1;当S<0时,表示已经没有可用资源,请求者必须等待别的进程释放该类资源,它才能运行下去。而执行一个V操作意味着释放一个单位资源,因此S的值加1;若S<0,表示有某些进程正在等待该资源,因此要唤醒一个等待状态的进程,使之运行下去。
正确的实现生产者消费者问题,一般需要三个信号量:
| 生产者 | 消费者 |
| P(empty) P(mutex) 向缓冲区增加元素 V(mutex) V(full) | P(empty) P(mutex) 向缓冲区增加元素 V(mutex) V(full) |
生产者、消费者的问题,其实就是线程间同步的问题,在java中,是通过synchronized、wait与notifyAll来实现的。
public class Buffer<V> {
private List<V> list = new LinkedList<V>();
private int size;
public Buffer(int size) {
this.size = size;
}
public void add(V v) throws InterruptedException {
synchronized(this) {
while (list.size() == size) {
this.wait();
}
list.add(v);
this.notifyAll();
}
}
public V take() throws InterruptedException {
synchronized(this) {
while (list.size() == 0) {
this.wait();
}
V v = list.get(0);
list.remove(v);
this.notifyAll();
return v;
}
}
}
add方法中对list.size() == size的判断相当于P(empty)操作,当缓冲区中没有空闲位置的时候调用wait方法强制阻塞当前线程同时释放this对象的锁,使得别的线程(消费者)有机会获得锁去取走元素。
list.size() == size的判断放进while中判断而不是if来判断是因为可能有多个生产者,当它们被唤醒时只有其中一个能真正向缓冲区增加元素,其它生产者会因为竞争失败再次处于阻塞状态;如果只有一个生产者线程,是可以使用if替换while的。
当生产者向缓冲区中增加元素后,通过this.notifyAll()方法通知消者费线程到缓冲区中去取元素。这里需要特别说明,在this对象上等待的线程,即可能是等待从缓冲区取的消费者线程,也可能是等待向缓冲区放的生产者。当调用this.notifyAll方法时,所有这些等待的线程都会被唤醒,某种程度上来讲,这种性能的损耗很大,第一:唤醒生产者线程完全没有意义;第二:被唤醒的消费者线程中只有一个能真正得到执行。另外,不难看出如果有多个生产者与消费者线程的情况下,使用notify()方法代替notifyAll()方法有可能发生活锁的情况。
调用notifyAll()方法的代价很高,其实我们是可以减少它的调用次数的。想想add方法中的notifyAll()方法的本意是想通知阻塞的消费者线程去缓冲区取元素,如果在生产者向缓冲区里增加元素时,缓冲区并不是空的,意味着此刻并不会有消费者因为缓冲区为空而等待,也就无需进行通知了。
采用条件通知的方式重新实现的add()方法如下。
public void add(V v) throws InterruptedException {
synchronized(this) {
int currentSize = list.size();
while (currentSize == size) {
this.wait();
}
list.add(v);
if (0 == currentSize) {
this.notifyAll();
}
}
}
使用内置锁有一个明显的缺陷,在像生产者、消费者这类问题上,多个线程可能在同一个条件队列上等待不同的条件谓词,如生产者向缓冲区增加元素后调用notifyAll()方法时,其它的生产者线程也会被唤醒。
另一方面,诸多被唤醒的消费者线程中也只有一个能真正得到执行。使用Lock与Condition可以使得等待特定条件谓词的线程处在同一个条件队列,从根本上解决了内置锁的缺陷。
使用显示锁重新实现的Buffer如下:
public class Buffer<V> {
private List<V> list = new LinkedList<V>();
private Lock lock = new ReentrantLock();
private Condition full = lock.newCondition();
private Condition empty= lock.newCondition();
private int size;
public Buffer(int size) {
this.size = size;
}
public void add(V v) throws InterruptedException {
lock.lock();
try {
while (list.size() == size) {
full.await();
}
list.add(v);
empty.signal();
} finally {
lock.unlock();
}
}
public V take() throws InterruptedException {
lock.lock();
try {
while (list.isEmpty()) {
empty.await();
}
V v = list.get(0);
list.remove(v);
full.signal();
return v;
} finally {
lock.unlock();
}
}
}
缓冲区是否已满和缓冲区是否为空分别由full与empty两个条件谓词表示,因而在唤醒的时候具有更强的针对性,而且只需要唤醒其中一个等待的线程(使用signal而不是signalAll),在竞争激烈的情况下可以减少很多无效的线程上下文切换与加锁操作从而避免性能损耗。
Lock对象还提供了tryLock、lockInterruptibly等方法,支持加锁时设置超时和响应中断等能力,比内置锁灵活很多。在jdk1.5中,显示锁的性能是明显好于内置锁的;在jdk1.6以后的版本使用了改进的算法管理内置锁,两者之间的性能差异几乎可以忽略。
内置锁虽然在灵活性方面差了些,但是有一个明显的优势:在线程转储中可以看到哪些调用帧中获得了哪些锁,对于分析死锁等问题时带来的便利是显示锁无法比拟的。 另外,未来提升内置锁性能的可能性应该会更高,因为它是JVM的内置属性,除非需要处理一些内置锁无法满足的问题,否则还是应该优先使用内置锁。
jdk1.5引入了Semaphore类,表示信号量,accqure方法相当于P操作,release方法相当于V操作。在掌握了生产者、消费者的解题流程后,使用Semaphore来实现Buffer也是很简单的事,使用信号量实现的Buffer如下:
public class Buffer<V> {
private List<V> list = new LinkedList<V>();
private Semaphore mutex = new Semaphore(1);
private Semaphore full;
private Semaphore empty = new Semaphore(0);
public Buffer(int size) {
full = new Semaphore(size);
}
public void add(V v) throws InterruptedException {
full.acquire();
try {
mutex.acquire();
list.add(v);
} catch(InterruptedException e) {
full.release();
} finally {
mutex.release();
}
empty.release();
}
public V take() throws InterruptedException {
empty.acquire();
try {
mutex.acquire();
V v = list.get(0);
list.remove(v);
return v;
} catch(InterruptedException e) {
empty.release();
throw e;
} finally {
mutex.release();
full.release();
}
}
}
当然了,这种方式实现的Buffer无论是性能,又或者可读性方面都不比前两种方式好,仅当作练习的话那还是很经典的一个例子的。
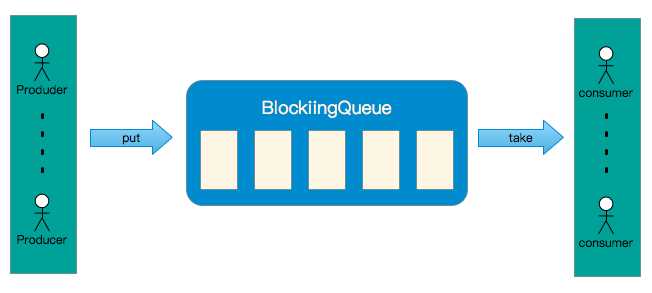
jdk1.5中新引入的BlockingQueue,它是专门为解决生产者、消费者问题而生的,它定义了四组方法以及五种不同的实现。
| Throws Exception | Special Value | Blocks | Timeout | |
| Insert | add(o) | offer(o) | put(o) | offer(o, timeout, timeunit) |
| Remove | remove() | poll() | take() | poll(timeout, timeunit) |
| Examine | element() | peek() | N/A | N/A |
Throws Exception:
BlockingQueue容量已满的情况下调用add方法会抛IllegalStateException。
Special Value:
offer方法与poll方法在BlockingQueue已满或为空的情况下分别返回flase与null值,而不会像add方法那样抛出异常。
Blocks:
BlockingQueue容量已满或为空的情况下,put方法与take将会阻塞。
Timeout:
与Special Value组方法行为类似,但是方法会阻塞直到超时时间到达。
另外,BlockingQueue中是不允许插入null的,如果你尝试向其插入null,方法将抛出NullPointerException。
java.util.concurrent包提供了五个BlockingQueue实现,分别是:
其中ArrayBlockingQueue与LinkedBlockedQueue是最常用的实现,它们之间的区别就像ArrayList与LinkedList的区别一样。ArrayBlockingQueue内部使用数组实现,在初始化的时候必须指定一个容量大小。 LinkedBlockingQueue内部使用链表结构实现,在初始化时容量作为一个可选参数,当未显式指定容量时,其上限为Integer.MAX_VALUE。
DelayQueue,每个被放进DelayQueue的对象都必须等待延迟过后再能取得它们,这意味着被放进DelayQueue的对象需要具备计算延迟的能力。 java.util.concurrent包提供了Delayed接口,只有实现了该接口的对象才能被放入DelayedQueue。
public interface Delayed extends Comparable<Delayed> {
public long getDelay(TimeUnit timeUnit);
}
Delayed接口不仅定久了getDelay方法,还继承了Comparable接口,个人猜测这是DelayQueue接口内部用于根据对象延迟时间排序用的。
PriorityBlockingQueue,顾名思义,从PriorityBlockingQueue取对象的顺序取决于对象的优先级,而不是把它们放入的顺序。对象需要实现java.lang.Comparable接口才可以被放入PriorityBlockingQueue。
SynchronousQueue是一个特殊的实现,它只能容纳一个对象。当线程尝试向SynchronousQueue放对象的时候将会被阻塞,直到有别的线程将对象取走。
前面提到的无论是内置锁还是显式锁,包括java.util.concurrent包中的Semaphore与BlockingQueue,本质都是采用了阻塞的方式来解决多线程间同步的问题的。 在竞争的情况下系统的性能会因为加锁产生上下文切换与调度延迟而降低,而非竞争的情况下多余的加锁操作本身也会消耗掉一部分性能。
CAS 指的是现代 CPU 广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。这个指令会对内存中的共享数据做原子的读写操作。简单介绍一下这个指令的操作过程:首先,CPU 会将内存中将要被更改的数据与期望的值做比较。然后,当这两个值相等时,CPU 才会将内存中的数值替换为新的值。否则便不做操作。最后,CPU 会将旧的数值返回。这一系列的操作是原子的。它们虽然看似复杂,但却是 Java 5 并发机制优于原有锁机制的根本。简单来说,CAS 的含义是“我认为原有的值应该是什么,如果是,则将原有的值更新为新值,否则不做修改,并告诉我原来的值是多少”。
java.util.concurrent.atomic包提供了大部分数据类型的原子封装,在原有数据类型的基础上,提供了原子性的操作方法,保证了线程安全。下面是采用CAS方式实现的Buffer:
public class Buffer<E> {
private static class Node<E> {
E item;
AtomicReference<Node<E>> next;
Node(E item, Node<E> next) {
this.item = item;
this.next = new AtomicReference<Node<E>>(next);
}
}
private final Node<E> dummy = new Node<E>(null, null);
private final AtomicReference<Node<E>> head = new AtomicReference<Node<E>>(dummy);
private final AtomicReference<Node<E>> tail = new AtomicReference<Node<E>>(dummy);
public boolean add(E e) {
Node<E> newNode = new Node<E>(e, null);
while (true) {
Node<E> t = tail.get();
Node<E> residue = t.next.get();
if (t == tail.get()) {
if (residue == null) {
if (t.next.compareAndSet(null, newNode)) {
tail.compareAndSet(t, newNode);
return true;
}
} else {
tail.compareAndSet(t, residue);
}
}
}
}
public E take() {
while (true) {
Node<E> h = head.get();
Node<E> t = tail.get();
Node<E> first = h.next.get();
if (h == head.get()) {
if (h == t) {
if (first == null) {
return null;
} else {
tail.compareAndSet(t, first);
}
} else if (head.compareAndSet(h, first)) {
E e = first.item;
if (e != null) {
first.item = null;
return e;
}
}
}
}
}
}
当竞争程度不高时,基于CAS的实现在性能上远远超过基于锁定的实现,在没有竞争的时候甚至更高。但是在竞争激烈的情况下,CAS的性能会比锁定的方式差很多,因为CAS是通过不断地重试、回退的方式处理竞争的,在竞争激烈的情况下会消耗很多的CPU资源;CAS的另一个缺点是会引发ABA问题。
要完全理解CAS方式实现的Buffer是有一定的困难的,如果您对非阻塞算法感兴趣,欢迎参考笔者的另一篇文章非阻塞算法CAS。